

AGBT 2021 took place virtually this year! But the conference was nevertheless the attention grabber of the week with a twitter storm, active reporting, and several commercial product launches as demonstrated by a slew of press releases.
Some of the hot topics discussed and showcased at the conference included single-cell genomics, spatial genomics, and SARS-CoV-2 genomic surveillance. Interestingly, we have seen spatial transcriptomics being the biggest topic at the AGBT 2019 conference and its development has since been reaching new heights every year, not only evidenced by the fact that Spatially Resolved Transcriptomics was named the “Method of the Year 2020” by Nature Methods, but also exhibited by several companies developing solutions for spatial gene expression visualization as summarized in this post. Another way of looking at this is how the NanoString platform has evolved since 2019, as presented by Joseph Beechem (CSO and SVP Research and Development at NanoString) in Figure 1. The successful journey of the GeoMx DSP platform over three years of AGBT from 84 plex to 22,000 plex now with the Whole Transcriptome Atlas.

Figure 1: Image credits NanoString.
A few meeting highlights:
Catherine Brownstein (Boston Children’s Hospital) discussed how Boston Children’s Hospital is building a genotype and phenotype program for young patients with severe neuropsychiatric disorders to help patients and parents get answers. One aspect covered in her talk were the challenges associated with detecting structural variations, such as translocations and inversions which stay undiagnosed in 50% of patients when using NGS or array-based technologies, but were uncovered when using the Saphyr Bionano System. She also emphasized that to achieve better clinical care an extensive two-way partnership that integrates research and clinical care is required (Figure 2).
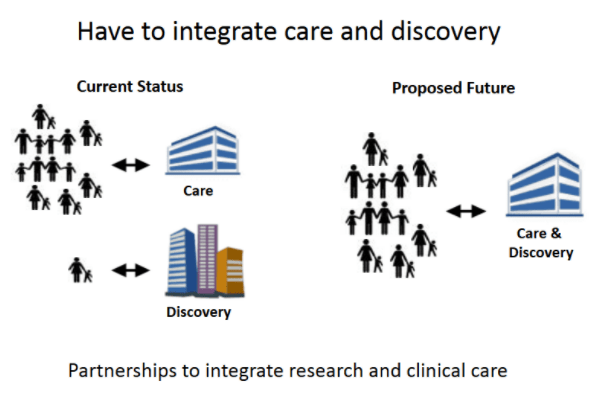
Figure 2: Image credits Catherine Brownstein.
Jeffrey Barrett (Director COVID-19 Genomics Initiative at the Wellcome Sanger Institute), gave a great talk on how the B.1.1.7 variant of the SARS-CoV-2 virus was discovered via genomic surveillance using next-generation sequencing. It exemplified the critical need for genomic surveillance to track the emergence and prevalence of new viral variants, to control the spread of the virus, and guide the development of new impactful therapeutics and vaccines. Chris Mason provided a genetic history of the SARS-CoV-2 virus moving around Earth. He presented a few interesting graphs originally created by Trevor Bedford (Fred Hutch) with one example demonstrating how limited early mutations like D614G spread globally during an initial wave (Figure 3), while summer and fall mutations were confined to regional dominance (Figure 4).

Figure 3: Image credits Trevor Bedford / Chris Mason.
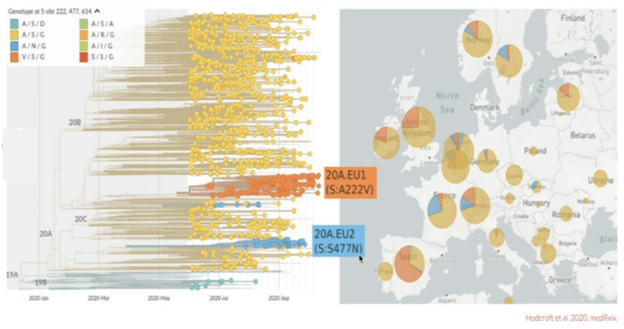
Figure 4: Image credits Trevor Bedford / Chris Mason.
As mentioned earlier, there were several interesting talks and poster presentations covering the aspects of single cell and spatial transcriptomics applications including the presentation by Andrew Yang (postdoc in Tony Wyss-Coray’s lab, Stanford University) reporting on a spatial transcriptomics atlas of the human brain vasculature in Alzheimer’s Disease and normal aging. A whole string of posters and plenary talks covering spatial transcriptomics can be found on the NanoString events site – all of the posters are downloadable.
Neville Sanjana (New York Genome Center) discussed applications of pooled CRISPR screens to identify regions that drive COVID-19 disease, or in other words understand the genes and pathways behind host dependency to fight COVID-19 with targeted drug discovery.
Karen Miga (UCSC | Human Pangenome Reference Consortium (HPRC)) who directs the Data Production Center at UCSC talked about the Human Pangenome project and the challenges associated with building and enriching data sets for a Pangenome from a population of 350 humans, which includes diversity (see Figure 5) and technological challenges to generate and analyze complete human genomes. The Human Pangenome Reference Consortium released year 1 sequencing data in mid-February which included data from various platforms, including PacBio’s HiFi data (produced by UW and WashU), Hi-C sequencing data (produced by UCSC), Strand-seq data (produced by EMBL), Oxford Nanopore data (produced by USCS), Bionano Genomics data (produced by Rockefeller) and Karyotypes & cell line microarray data (produced by Coriell Institute and CHOP) – see Figure 6 .

Figure 5: Image credits Karen Miga.

Figure 6: Image credits Karen Miga.
Also noteworthy, was an update of the All of Us Research Program provided by Josh Denny (CEO of the NIH All of US Research Program) which has currently about 366,000+ participants (Figure 7). Denny talked about the Workbench for researchers, an open platform which provides access to a list of public (anonymized) and registered tiered data (which provides access to registered researchers), and the data roadmap they are pursuing (see Figure 8).

Figure 7: Image credits Josh Denny.
Some key All of Us numbers – as of January 19, 2021) include:
- 366,000 participants
- 233,000 electronic health records
- 272,000 participants with completed initial steps of the program
- 279,000 bio samples – ~4,500 are processed on a weekly basis
- 27,987 genotyping results
- 10,196 whole genome sequencing results
- 9,954 participants who viewed their genetic ancestry or traits results

Figure 8: Image credits Josh Denny.
A few interesting quotes
- Natalie Prystajeck (BC Centre for Disease Control): “ As soon as I make a slide, it’s out of date” – as she describes the work they are doing on genomics sequencing of the SARS-CoV-2 variants.
- Chris Mason (Well Cornell Medicine):
- “ Each COVID-19 tissue type studied showed a distinct pattern of disrupted gene expression.”
- “10x Genomics is showing that ‘routine 1M single-cell experiments’ are coming our way.”
- Karen Miga (UCSC): “We need to generate a complete and analyzable human genome at the population-level; presents What’s challenging us? (1) Population Representation (2) Technology (3) Phasing (4) Data Management and Standards… embedded across all is ethics and policies!”
- Jonas Korlach (Pacific Biosciences): “This concept of having a genome as a platform and mining this platform for information that may be needed during the different stages of a person’s life, and applying it for different types of disease areas, is a powerful paradigm for precision medicine.”
- Josh Denny (All of Us): “Understanding genetics helps proper disease and drug research, yet there’s a lack of diversity in genomic studies. All of Us I will recruit over 1 million participant, starting with community engagement.”
- Julianna LeMieux (Genetic Engineering & Biotechnology News): “At this year’s AGBT meeting, the biggest stir was caused by spatial transcriptomics, a technique to visualize gene expression in the context of a tissue.”
- Neil Miller (Children’s Mercy): “HiFi for previously unsolved rare diseases shows better accuracy, calls SVs, can phase variants and distinct haplotypes, identifying pathogenic variants in patients, useful in patients without parental data”.
- Bert Vogelstein (Ludwig Center at John Hopkins Kimmel Cancer Center): “We have to move from the understanding of cancer…to treatment and diagnosis of cancer. Despite not knowing what many of these mutant genes do, we can still treat it.
Product launches/press releases
Single-cell/spatial genomics
- NanoString launches technology access program for the spatial molecular imager (SMI) platform and showcases spatially resolved transcriptomic research at AGBT 2021
- Rebus Biosystems launches automated spatial omics platform
- Vizgen Debuts Next Generation Genomics Platform at AGBT The solution combines single-cell and spatial genomics analysis in one integrated system
- OnRamp Bio Debuts as ROSALIND at AGBT and Launches First-of-its-Kind
Single Cell Data Analysis Solution
Sequencing
- Illumina and R-Pharm Secure Registration for Two Complete IVD Sequencing Platforms in Russia
- Miroculus Collaboration Pushes Boundaries of PCR-free WGS
DNA synthesis
CRISPR
Other






