

Data is the blood being pumped through the organism of personalized medicine and will be – as has always been – the key to the identification of novel biomarkers and potential new therapeutics. We have never had access to more data than today. Within preclinical and clinical research, we collect blood, tissue and behavioral data, process them in our analysis pipelines and cross-correlate with outcome, phenotypic, and further Real-World Evidence (RWE) data.
However, while committing millions to the generation of new data we haven’t spent a measurable effort on getting control of the data in a connected and scalable way. Our data scientists and AI/ML experts spend more time searching for and integrating datasets than on their primary job of analyzing and extrapolating from it. It’s slowing down how we drive science within our institutions and worse – across the industry (COVID-19 is a nice example of how important and hugely beneficial quick and reliable data sharing and integration is to inform and orchestrate global vaccine/therapy development, lockdown procedures, and viral surveillance).
FAIR Data is the solution to existing data challenges
In order to overcome these data challenges, the concept of FAIR data was born and developed by a group of biopharma, academia, government, and publishing representatives – findable, accessible, interoperable and reusable data for both human and machines (Figure 1). While the development of globally accepted implementation patterns is still ongoing (Magagna, 2020), FAIR data can be reduced to the principles outlined in Figure 1 below (adapted from Wise, 2019).

Figure 1: Criteria for and direct value generated by FAIR data.
How we FAIRify
The focusing question within the FAIR data journey is a “use case”. While overused as a term and often understood in different ways, well-defined use cases give us the necessary structure to prioritize and streamline our efforts based on business objectives. As depicted in Figure 2, the definition of the use case based on a scientific question marks the start of the FAIRification process. It defines the required data scope (e.g., pre-clinical, clinical, RWE) and, in cases where we first need to find the data, it directly guides searching for and collecting of the data. Based on the input from our domain experts (e.g., scientist, bioinformaticians, laboratory technicians), we map (meta)data to available ontologies, apply unique identifiers and access/privacy rules, provide provenance information, and finally integrate data within a federated network of data sources and applications. The data is linked with related datasets across different systems and applications through a virtual knowledge map and is easily searchable through a variety of visualization apps, dashboards, and catalogs.
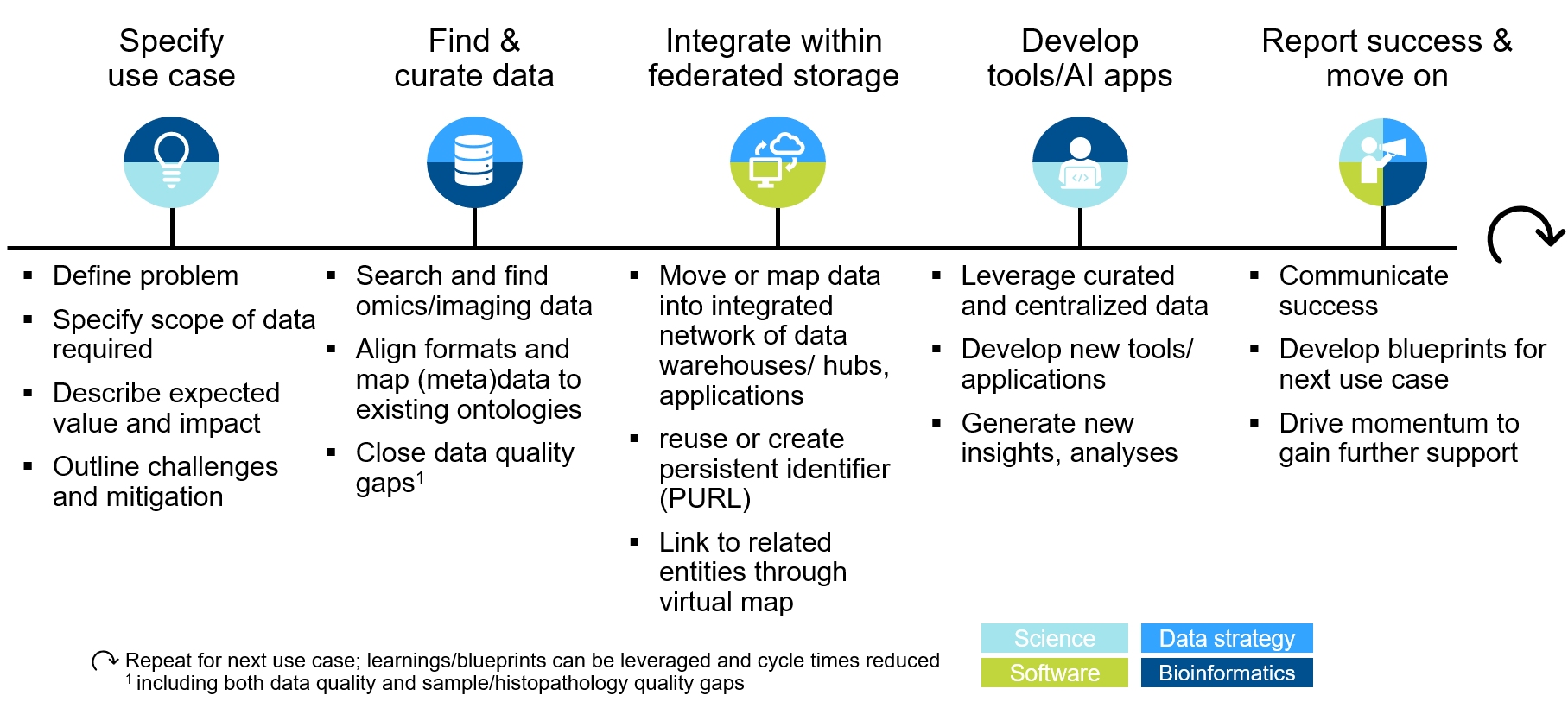
Figure 2: Use case based data FAIRification.
As simple as it sounds, the data-centricity journey is a strategic long-term investment that requires:
- Additional skills and expertise (e.g., data curation/engineering, automation, semantics).
- Access to technologies enabling FAIR data management and processing.
- Science, technology, and data minds working hand in hand to generate a data-centric environment that reflects the domain expert’s way of thinking and data handling.
Even more important than the above three statements, is strong leadership support. Data centricity requires a change within the daily routines and workflows of our businesses. Leadership needs to be convinced to make the necessary investment through short term business value generation and promote transparency on the mid- and long-term opportunities which include but are not limited to:
- Accelerated and novel insight generation/biomarker identification through integrative analysis of data across studies, entities, therapeutic areas, and beyond.
- Increased efficiency within the data analysis and/or algorithm development pipelines thanks to a time decrease in searching for and cleaning up data (within day-to-day operations).
- Increased trust in data/insights due to improved provenance and understanding of the datasets, and therefore improved data-driven decision making.
There still, lie miles ahead of us on our FAIR data journey but the baseline is set and it continuously gains momentum. Our team within AstraZeneca’s Translational Medicine will push hard to realize our FAIR data ambitions to expand the boundaries of science and help patients in a science-led and data-centric way.
Some useful FAIR resources

- The GO Fair resources which might be useful for any FAIR endeavor. It has a collection of their GO FAIR materials, interesting papers and publications, and tools.

- The Pistoia Alliance FAIR Toolkit provides use cases that exemplify the benefits, how-to methods, training, and change management of FAIR implementation.

- The FAIR Cookbook by FAIRplus collates protocols for making data FAIR and examples of dataset FAIRification. FAIRplus also started the FAIRplus fellowship program to offer comprehensive training in FAIR data management.
Sources
Magagna, Barbara, et al. Reusable FAIR Implementation Profiles as Accelerators of FAIR Convergence. (2020).
Wise, John, et al., Implementation and relevance of FAIR data principles in biopharmaceutical R&D. (2019) Drug Discovery Today, 24.4 (2019): 933-938.

Dr. Magdalena Wienken – enlightenbio Guest Blogger
Magdalena leads the Translational Medicine (TM) Data Strategy team at AstraZeneca, Computational Pathology in Munich. As part of the TM Data Strategy team she is pushing towards making data discoverable, interoperable, and reusable across departments, applications, and processes within AstraZeneca. She is a strong believer in cross-functional teams and the necessary merge of science, data, and technology to transform patients’ therapy and quality of life.
Magdalena has a background in Human Biology/Molecular Medicine with a PhD in Molecular Oncology focusing on computational cross-omics analyses. Her passion for digital and data strategies emerged from a three years working stint at Accenture Strategy. There, she led the development of innovative business strategies at the intersection of personalized medicine and digital healthcare working with pharma companies within the area of Germany, Austria, and Switzerland.






