

This month’s “Company Spotlight” takes a closer look at Deepcell, a company that is building a platform for the identification, isolation, and classification of viable cells based on their morphological distinctions for use in discovery, translational research, diagnostics, drug discovery, and therapeutics.

Mahyar Salek, President, CTO & Co-Founder of Deepcell discussed with us in detail Deepcell’s platform, its approach to developing viable cell-based applications, and its vision to solve some of the drug discovery and development challenges via cost-effective and efficient solutions.
Deepcell is a company that started out of Professor Euan Ashley’s lab, where Madison Masaeli did her post-doc and together with Euan Ashley and Mahyar SalMadison Masaeliek invented the AI-based single-cell analysis and sorting technology which is the heart of the Deepcell platform. The company spun out in 2017 and has now more than 60 employees with over 30 open positions on their website.
The following summarizes my dialogue with Mahyar Salek.
EB: First off, congratulations on the most recent Series B funding round of $73M, this is substantial. Exciting news.
You have developed an AI-based cell identification, isolation, and classification methodology that is dependent on the morphological features of a specific cell population. What will you be able to accomplish with this latest funding round of $73M? What from a technological perspective will this allow you to craft? What product advancements will you concentrate on?
Mahyar Salek: We’re planning to take the platform from the current stage – where we’ve demonstrated that its technology is performing with the science as expected – to a next level product that is accessible to our target market, fits within our customer’s workflow, and addresses their needs and how they want to use the platform. Furthermore, we are also taking early steps into commercialization efforts. This is where the majority of the funds will go. We are also making new bets into the future of this technology.
So, the activities are in R&D, advancing along the technology roadmap, and productizing and early commercialization efforts.
EB: How big is Deepcell now and how are you expecting to grow? Do you think you will quickly add headcount or will the company slowly evolve over the years? How much of the product still needs to be developed before you advance to next steps and how much of the product development is done in partnerships?
MS: Right now, we are over 60 people and we are growing in every function, every department. We are also adding new departments and functions to what we already have. We are planning a very aggressive growth. It’s been a conscious decision to bring the best and the brightest to join Deepcell, and we’re going to continue to do so. It’s certainly a challenge with the mandate we have to grow really fast in order to hit our milestones.
And yes, we are developing our product alongside the scientific community. And we like to think about the scientific community – the labs and the research institutes – as our partners. We also believe this is the right way to commercialize this product. Building on early partnerships, the early collaborations with the scientific community, with the research community is the right way to do it.
“Any product in the life science space that is of this disruptive nature should be endorsed and should be validated by the researchers and the groundbreakers first.”
EB: How did your technology evolve and how did the company Deepcell get started? Can you share with us a bit about the story of the early days?
MS: It all started with scientific curiosity or technological curiosity. Madison, our CEO, and I were discussing her project she was working on at the time in the lab of Professor Euan Ashley at Stanford. It seemed that the microfluidic component was a critical centerpiece. Specifically, sorting of a cell to the right channel was validated with a visual inspection step. We had this aha moment: “why can’t we have this inspection step be done by a source of non-human intelligence?” The next immediate step to that curiosity was, well, it doesn’t have to be passive inspection, rather AI could be the equivalent of a policeman at the intersection directing different cells towards different streets. So that was the original idea.
And as we were exploring this scientific curiosity, we learned more and more about the different types of industries and applications that would benefit from exactly this type of technology. Originally, we were intrigued by non-invasive prenatal testing (NIPT) applications – a specific type of fetal cells, fetal nucleated blood cells, grabbed our attention: They have no good biomarkers to be identified by, yet have a very distinct morphology. And if you are able to capture these cells from maternal circulation, you would have a non-invasive diagnostic test. We’re intrigued by this specific application, but we quickly realized that there are many more applications within the realm of diagnostics, as well as, within therapeutics, drug discovery and development, cell therapy, and beyond.
Hence, the best way to address this wide range of applications is to introduce the technology as a platform. We take advantage of our client base and collaborators to be able to scale and deliver many applications as opposed to focusing on one. Obviously, building a platform is a momentous job, but that’s the decision we’ve made and we think we made the right decision.
We started the company in the fall of 2017, but before that the “project” was already active at Stanford – Madison received a few grants to work on this while being a postdoc. Our first patent, which we licensed from Stanford, was issued while Madison was at Ashley’s lab and performing early investigations.
EB: When will you launch your platform, or, in other words, what are some of the timelines you can share with us?
MS: At this moment, I don’t really want to discuss exact timelines, but I will speak to the general roadmap of how this would look like. The first phase of the platform launch is a program which we call TAP, or Technology Access Program: At first, our collaborators send us samples which we are processing in-house. This is already work in progress – we’ve made some collaborator announcements. This will be followed by placing the instrument at the sites of a select group of collaborators. There are a few top tier labs in academia and industry we’re collaborating with, and they’ll get the instrument. This will allow them to not only get first-hand experience with our technology, but also be able to perform their own proprietary post-downstream or post-process activities of what they want to do with those sorted cells. So that’s the next step. Some of these early testers, in addition to some of the new customers will then enter what we call the early access program, which will be a limited edition commercial launch.
EB: What are some of the scientific and technical needs Deepcell is addressing with this platform in the cell research sector? How would you summarize that? How will this disrupt the market or the entire sector?
MS: There is a gap in how current tools, equipment, and analytical solutions make sense of genomic data, compared to the ones that try to understand phenotype level data, the latter of which is way behind. There’s a big irony there, because we’ve been processing phenotype data much longer, and with a greater track record of success compared to genotype data. This goes back all the way to when we invented the microscope, or even before that.
In fact, there are many more clinical tests and activities that are based on morphology and generally phenotype information rather than the molecular analysis of cells. With this premise, we started Deepcell with its technology, because there is a need for how we are dealing with phenotype data. This transformation, or upgrade, must be able to bridge phenotype with genotype data. There is evidence that bridging these two types of data will create bigger value compared to the sum of the two. This multimodal approach will provide deeper insight and understanding into how the biology in complex systems work.
In addition to the deeper understanding, we’ve heard over and over again that there is value in methods that keep cells intact. More often than not (sorting cells) is just the beginning of a multi-step process where you actually want to do something with these cells.
And then the third one, there is a need to look at cell biology without bias or a hypothesis. Biology is like a dark room. When you use a certain biomarker within that dark room, all of a sudden you illuminate a certain color or a certain texture. This provides a partial view into some properties and the arrangement of the objects that occupy that room. But what you really want is to turn up the light to see everything. Our technology is a step towards that direction.
EB: You first had to build a cell morphology atlas so that you could train your system to identify and classify cells. Do you have to train each single cell type before you can identify and classify it, or can the system learn and identify cell types it has never seen before?
MS: The answer is yes and no. So yes, in the sense that we need something to start building some anchors. We do that through many ways. There is rich molecular data, which comes from many experiments. There is traditional FACS data, or traditional cell biomarker data for different types of cells, or for immune cells the cluster of differentiation is a very interesting data set as well. In addition to these anchors, there is data that summarizes what happens at different levels. For example, patient-level data is a very good anchor point, there is disease progression data, functional data, or as an example of oncology application the metastatic status data of a cell. These data points are very valuable, but are inherently sparse.
What’s interesting about the machine learning techniques, is their impressive success in making sense out of sparse data sets. For instance, you could have a very small portion of your data set labeled, and you could learn a lot more with the unlabeled rest of your dataset with those smaller data labels.
EB: What happens when you start working with a new company or start a new partnership? Do they have to provide cell population and morphology data for training, if they, for example, work with a disease that is associated with a very specific cell morphology for which you don’t have yet data that can be used to train? Or do they provide image data? Or is it sufficient for you to use those anchor points that you have in your system to train the data?
MS: It depends on exactly what the problem is we’re trying to solve. In some cases, we don’t even need any metadata for the problem that we are solving because we already have enough anchor points, and we already know that space very well. Though, in other situations, maybe the space is so new, and we know so little that we need booster data to get to some quick progress or success in that space. Furthermore, one of the unique aspects of our technology, which differentiates us from digital pathology or AI-powered digital pathology, is that our own technology can generate ground truth through sorting cells and retraining based on the output of the process. We could actually form a hypothesis, and then sort the cells based on that hypothesis. Then we validate whether this was correct or not, because now we have the sorted cells for downstream assays. That’s categorically different from a type of technology for which you need an external, annotated data set or a group of human experts to validate what AI provides, because our ground truth can be generated using our own technology at scale.
EB: You built the cell morphology atlas, which is based on image data, but your platform sorts live cells which adds a dimension that is lost in image data. How does this affect your cell sorting results?
MS: The asset we are building is multimodal. Images are a cornerstone of our atlas (see also Figure 1), but the image data is a lot more powerful/useful if it’s coupled with molecular and functional data. Providing this combination in the anchor data set is what makes us unique. Now if we add patient data, this will become even more powerful. We’re building the capability to have all of this being part of the atlas. This is our vision.
EB: I assume this combination includes the proprietary AI capabilities you have developed as well, this in addition to the data?
MS: Yes, the AI capabilities come in various flavors. You can imagine that the atlas could grow really large. Processing that data and deriving insights from a huge dataset could eventually get really challenging. One way we use AI is to mine those insights from the Atlas. Let me explain this with an example. We have proprietary ways to cluster the data in our atlas. When asking a question, for example: What are the closest cell types from a morphological point of view or based on a specific molecular makeup? Or, Is there any disease in my atlas that has a similar recognized morphological phenotype than the one that I’m already looking at? So, you could ask a lot of those questions and in my opinion, the only way that you could practically answer those questions is by applying powerful computational tools.
EB: Can you speak to the size of your database in any way, and where do you get the images with the data from?
MS: I need to check every day, but right now we have about 1.5 billion cell images along with annotations and other modalities of data in our atlas, and this is only growing. I feel like we are actually only at the beginning of the growth.
We generate images ourselves. We receive samples from commercial vendors and partners.
EB: Is there a way to say how many diseases, tissues, and organs you are covering with your atlas?
MS: There is not a simple answer to this. If you combine cell types, cell states, and functions, it could easily be thousands, if not tens of thousands.
EB: What are the various possible applications your platform supports for the pharma/biotech sector? Can you go over a couple of those applications?
MS: Yes, we believe there are opportunities for pharma with our platform in drug discovery and drug development. Many of the experiments the pharma industry is performing could be simplified or made more efficient with capabilities our platform supports. I’ll give you one example: In many scenarios, if you were able to look at the morphological changes of cells, you could better understand and predict the cell behavior within an experiment. As of now there are no good ways to do that quantitatively. And being able to tie this to the molecular readout you have, for example, with a functional assay, this would expedite drug discovery. Or in other words, one could screen for more efficacious drugs based on the response of different cell types to a drug via visual morphological changes.
Another opportunity is in the cell therapy or cell manufacturing area, at the core of which is a better understanding of cells. In order to better understand which cells are more potent versus others, and how one can faster, and more efficiently screen cells of interest. To achieve this one could apply quality control based on cell morphology.
EB: What are some potential applications on the clinical side?
MS: As I mentioned earlier, our original motivation for this technology was its potential for NIPT, which still remains of great interest. We believe that the future of this technology can be clinical-heavy, yet we also understand that the clinical space is slower to adopt, needs more data points, and more proof points. For now though, our approach is to democratize our technology and make it accessible to as many researchers as possible, and then let the science speak which we believe is the best way to win the market. But ultimately, our goal is to make our platform accessible for clinical applications.
EB: Last, but not least, what could a very typical research-type application in academia look like?
MS: Every single researcher does something unique and therefore it is hard to characterize what is a typical application. We’ve so far identified three general use cases in what we are calling the morpholome: enrichment, profiling, and discovery. But the last use case is indeed a placeholder for many: This for example includes, “understanding malignancies”, and implies it’s not just about enriching or sorting for malignant cells but understanding the complex tumor environment and the complexity of the disease through high dimensional assessment of morphology. Basically, understand the interplay between the immune cells and the malignant cells and other types of cells and how they reshape and reform as they get into different stages or different states of the disease.
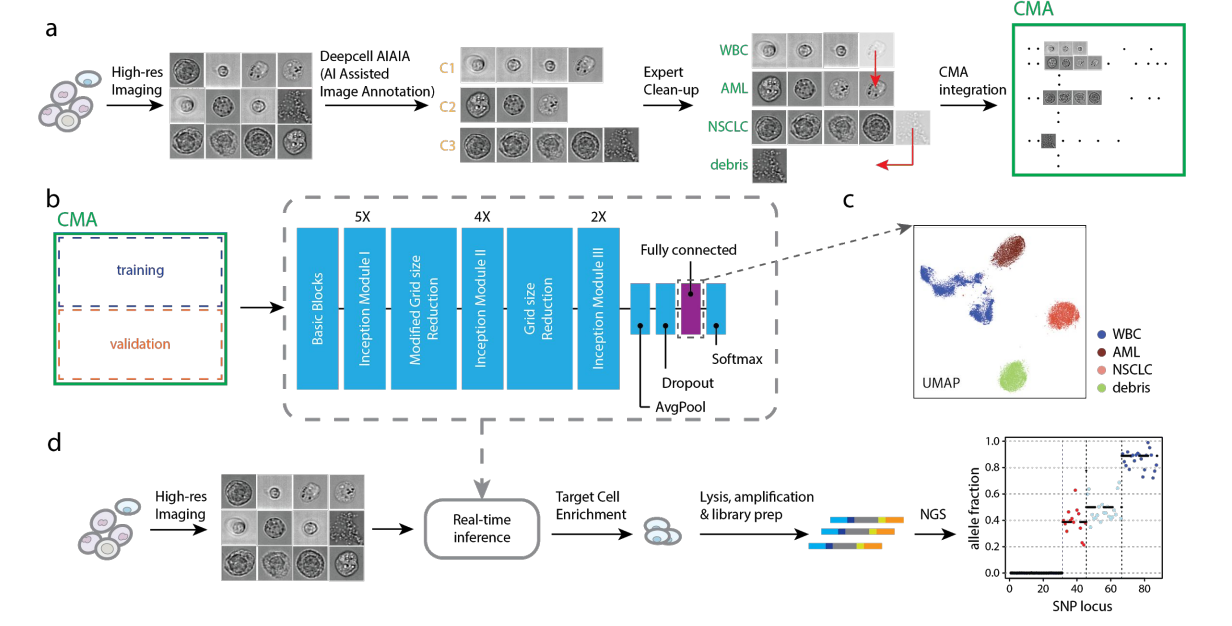
Figure 1: Depiction of model training and label-free sorting. High resolution images of single cells in flow are stored and integrated into a Cell Morphology Atlas (CMA). The CMA is used to generate both training and validation sets for the classifier model. During a sorting experiment, the pre-trained model is used to infer the cell type (class) in real-time. The enriched target cells are retrieved from the device and characterized.
(Source: Deep learning enables real-time classification and label-free enrichment of cells in flow | Chang et al.)
EB: How will AI-based technologies disrupt the research or cell research sector, specifically. What should we expect in the next five to ten years from now?
MS: There’s a lot of great work being done in many ways and in many areas, and I don’t want to speak on behalf of the entire industry. I do expect that at one point we will be able to bridge across all this great work, and do so much better than right now. Many technologies are built in silos and some provide very targeted intelligence. Eventually what will happen, is that we will be able to bridge these different modalities, which will allow us to arrive at new insights that we would have not been able to harvest in isolation from a single modality. This is what we do right now with our platform: We are combining technologies which allow us to uncover new insights. We are combining AI with data and cell imaging.
AI developments have advanced tremendously, specifically in the imaging sector which historically has led machine learning research activities. Other modalities such as text and genomic data are about to catch up, and from what I understand they’re catching up to the state that we can understand them as well as we understand image data. I believe in the near future there will be even more opportunities to bridge these different modalities and make sense of the data beyond what is already achievable right now. Part of it is because if we can apply similar techniques to these different modalities, we will be in a good position to combine them, which will allow us to understand a hybrid view of these data. In practical terms, this will translate into much more streamlined pipelines for diagnostics, for drug discovery, and drug development. I believe that eventually we will have a new generation of experiments and clinical trials because of AI-driven selection which will allow us to cut costs and save lives. Being able to navigate through various views from molecular to cellular, to tissue, to patient, and to population provides a totally new perspective with new insights which we would not be able to gain if we were only looking at one level.
EB: What are some of the biggest challenges the industry, or the cell research sector specifically, still needs to overcome to be able to make use of the multi-level data approach you described in the prior statement?
MS: One major challenge, as I see it, is the lab staff not being versed enough in data science and vice versa (data scientists understanding the lab work). While it is starting to happen, it happens at a slower pace than I wish it was happening. And granted, this is not easy. Biology is hard and complex. At the same time, data science has its own complexity. Hiring people that have both skills is a challenge, as they’re the unicorns. They’re the true unicorns out there, and we need more of those. We need more of those to advance at a faster pace. So, I would say the number one challenge is overcoming the bottleneck of people and their skillset.
Another point is that healthcare regulators need to upgrade their viewpoints with new technologies entering the sector. For instance, now we’re capable of seeing things in a much faster cycle because of how we’re collecting and analyzing data compared to how we used to. For example, many of the in silico and in vitro experiments can now be done at a much faster pace because we have the data tools. Does it mean that we could actually run faster as a whole, and have a drug discovery pipeline at a fraction of the cost? Probably, yes. But that also means that the regulatory bodies need to understand and respond accordingly. They need to ask those hard questions so that they get comfortable with this.
The third component is the perception of AI and what it can do. While AI can and will achieve a lot – and we already take it for granted – we are still dependent on future progress. Really, AI is not nearly the general intelligence system yet we want it to be. There’s still a lot of work that needs to be done, specifically when it comes to biology-based data. We are not that familiar yet with that type of data. Scientific and technological progress still needs to be made.
“…AI is not nearly the general intelligence system yet we want it to be. There’s still a lot of work that needs to be done, specifically when it comes to biology-based data.”
EB: Who do you view as your competition?
MS: There are definitely other people and companies that are looking at this space which I believe is a very fortunate thing. I welcome competition because ultimately more competition translates into a drive for better, higher quality solutions. On the startup side, there are a few companies that are looking into collecting content, such as high-resolution images of cells in various forms which I think is pretty exciting. Then there are also startups that are playing with the idea of how much real-time computation and AI can be applied to these cellular workflows. Those are all great initiatives.
Of course, there are also the more conventional technologies like cell sorting which has been out there as a gold standard ever since. But even those technologies are reinventing themselves with the new trend of molecular and single cell analytics.
So yes, we see competition from both smaller companies, as well as some awareness and some activities from the bigger and established ones.
“I feel like the space is heating up quite rapidly. If you just look at the publications in this space, it’s all very exciting and I’m very encouraged by it. I think, all in all, we as a community would benefit from more activities. There are huge opportunities we couldn’t even dream of unlocking just five years ago.”
EB: Is there anything else you would like to share with the enlightenbio audience?
MS: Right now we are looking for exciting partners and applications to help with. While we have a full pipeline of different applications, we are always looking beyond those for new exciting opportunities we can get our hands on. So please, reach out to us if you have an exciting application and want to work with us.






